
[方策ネットワーク]
第8章1〜4
USIエンジンの実装
policy_player.py
y = self.model(x)
yは活性化関数を通す前の出力層の値。
logits = y.data[0]
活性化関数を通す前の出力層の値をlogitsという変数に代入。ロジットという単語は活性化関数を通す前の出力層の値の意味。
[0]の意味
y.dataの一例
[[-4.137782 0.12063725 -4.907426 … -5.663455 -6.104148 -7.8398824 ]]
y.data[0]
[-4.137782 0.12063725 -4.907426 … -5.663455 -6.104148 -7.8398824 ]
xを生成するときにfeaturesを[]で囲ってからnp.arrayにしている。
x = Variable(cuda.to_gpu(np.array([features], dtype=np.float32)))
だからy.dataは[ [ ] ]の形になっている?[ ]で囲った意味は?
y.data[0]の要素数は、(20 + 7) * 9 * 9 = 2187
20は移動方向(UP、DOWN、・・・)、7は持ち駒の種類。
合法手、違法手全部合わせた指し手の数。
10章で出てくる価値ネットワークでは[ ]で囲わずにxを生成している。
x = Variable(cuda.to_gpu(np.array(features, dtype=np.float32)))
10章では先に合法手でフィルタリングしていたり、少し違う。単純対比すると混乱する。
probabilities = F.softmax(y).data[0]
probabilitiesは[1.3974859e-04 9.8799672e-03 6.4728469e-05 … 3.0391777e-05 1.9559853e-05 3.4478303e-06]
GPU/CPUとPCの自動切り替え
iMacでもColabでも実行できるようにしておく。
# 環境設定
#-----------------------------
import socket
host = socket.gethostname()
# IPアドレスを取得
# google colab : ランダム
# iMac : xxxxxxxx
# Lenovo : yyyyyyyy
# env
# 0: google colab
# 1: iMac (no GPU)
# 2: Lenovo (no GPU)
# gpu_en
# 0: disable
# 1: enable
if host == 'xxxxxxxx':
env = 1
gpu_en = 0
elif host == 'yyyyyyyy':
env = 2
gpu_en = 0
else:
env = 0
gpu_en = 1if gpu_en == 1:
from chainer import cuda, Variable def __init__(self):
super().__init__()
if env == 0:
self.modelfile = '/content/drive/My Drive/・・・/python-dlshogi/model/model_policy'
elif env == 1:
self.modelfile = r'/Users/・・・/python-dlshogi/model/model_policy' # 学習して作成した方策ネットワークモデル
elif env == 2:
self.modelfile = r"C:\Users\・・・\python-dlshogi\model\model_policy"
self.model = None if gpu_en == 1:
self.model.to_gpu() if gpu_en == 1:
x = Variable(cuda.to_gpu(np.array([features], dtype=np.float32)))
elif gpu_en == 0:
x = np.array([features], dtype=np.float32) if gpu_en == 1:
logits = cuda.to_cpu(y.data)[0]
probabilities = cuda.to_cpu(F.softmax(y).data)[0]
elif gpu_en == 0:
logits = y.data[0]
probabilities = F.softmax(y).data[0]戦略設定
グリーディー戦略かソフトマックス戦略かどちらかを選ぶようにする。本の書き方がわかりづらかったので書き換えた。
# 戦略
# 'greedy': グリーディー戦略
# 'boltzmann': ソフトマックス戦略
algorithm ='boltzmann'
if algorithm == 'greedy':
# ①確率が最大の手を選ぶ(グリーディー戦略)単純に確率が最大の要素を返す。
selected_index = greedy(legal_logits)
elif algorithm =='boltzmann':
# ②確率に応じて手を選ぶ(ソフトマックス戦略)確率が大きい要素をランダムに返す。
selected_index = boltzmann(np.array(legal_logits, dtype=np.float32), 0.5)全コード
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 環境設定
#-----------------------------
import socket
host = socket.gethostname()
# IPアドレスを取得
# google colab : ランダム
# iMac : xxxxxxxx
# Lenovo : yyyyyyyy
# env
# 0: google colab
# 1: iMac (no GPU)
# 2: Lenovo (no GPU)
# gpu_en
# 0: disable
# 1: enable
if host == 'xxxxxxxx':
env = 1
gpu_en = 0
elif host == 'yyyyyyyy':
env = 2
gpu_en = 0
else:
env = 0
gpu_en = 1
# 戦略
# 'greedy': グリーディー戦略
# 'boltzmann': ソフトマックス戦略
algorithm ='boltzmann'
#-----------------------------
import numpy as np
import chainer
from chainer import serializers
import chainer.functions as F
if gpu_en == 1:
from chainer import cuda, Variable
import shogi
from pydlshogi.common import *
from pydlshogi.features import *
from pydlshogi.network.policy import *
from pydlshogi.player.base_player import *
def greedy(logits): # 引数に指定したリストの要素のうち、最大値の要素のインデックスを返す
# logitsとはニューラルネットワークでは活性化関数を通す前の値のこと
return logits.index(max(logits)) # リスト.indexは引数に指定した値がリスト自身の何番目の要素かを返す。
def boltzmann(logits, temperature):
logits /= temperature # a /= b は a = a / b の意味
logits -= logits.max() # a -= b は a = a - b の意味。 マイナスの値になる。最大値は0。
probabilities = np.exp(logits) # x =< 0 のexp関数
probabilities /= probabilities.sum()
return np.random.choice(len(logits), p=probabilities) # choice(i, p=b)は0~i-1までの数値をbの確率でランダムに返す
class PolicyPlayer(BasePlayer):
def __init__(self):
super().__init__()
if env == 0:
self.modelfile = '/content/drive/My Drive/・・・/python-dlshogi/model/model_policy'
elif env == 1:
self.modelfile = r'/Users/・・・/python-dlshogi/model/model_policy' # 学習して作成した方策ネットワークモデル
elif env == 2:
self.modelfile = r"C:\Users\・・・\python-dlshogi\model\model_policy"
self.model = None
def usi(self): # GUIソフト側:起動後にUSIコマンドを送信する。USI側:id(とoption)とusiokを返す。
print('id name policy_player')
print('option name modelfile type string default ' + self.modelfile)
print('usiok')
def setoption(self, option):
if option[1] == 'modelfile':
self.modelfile = option[3]
def isready(self): # GUIソフト側:対局開始前にisreadyコマンドを送信する。USI側:初期化処理をしてreadyokを返す。
if self.model is None:
self.model = PolicyNetwork()
if gpu_en == 1:
self.model.to_gpu()
serializers.load_npz(self.modelfile, self.model)
print('readyok')
def go(self):
if self.board.is_game_over():
print('bestmove resign')
return
features = make_input_features_from_board(self.board)
if gpu_en == 1:
x = Variable(cuda.to_gpu(np.array([features], dtype=np.float32)))
elif gpu_en == 0:
x = np.array([features], dtype=np.float32)
with chainer.no_backprop_mode():
y = self.model(x)
if gpu_en == 1:
logits = cuda.to_cpu(y.data)[0]
probabilities = cuda.to_cpu(F.softmax(y).data)[0]
elif gpu_en == 0:
logits = y.data[0] # 活性化関数を通す前の値を変数に代入。下記のように1要素目を取り出す。
# y.dataは、 [[-4.137782 0.12063725 -4.907426 ... -5.663455 -6.104148 -7.8398824 ]]
# y.data[0]は、 [-4.137782 0.12063725 -4.907426 ... -5.663455 -6.104148 -7.8398824 ]
# ちなみにy.data[0]の要素数は、(20 + 7) * 9 * 9 = 2187
probabilities = F.softmax(y).data[0]
# probabilitiesは[1.3974859e-04 9.8799672e-03 6.4728469e-05 ... 3.0391777e-05 1.9559853e-05 3.4478303e-06]
# 全ての合法手について
legal_moves = []
legal_logits = []
for move in self.board.legal_moves:
# ラベルに変換
label = make_output_label(move, self.board.turn) # 移動方向+持ち駒の27と移動先の9x9をlabelに代入
# 合法手とその指し手の確率(logits)を格納
legal_moves.append(move)
legal_logits.append(logits[label]) #labelは指し手のインデックスを表す。その指し手の確率をlegal_logitsに代入。
# 確率を表示
print('info string {:5} : {:.5f}'.format(move.usi(), probabilities[label]))
if algorithm == 'greedy':
# ①確率が最大の手を選ぶ(グリーディー戦略)単純に確率が最大の要素を返す。
selected_index = greedy(legal_logits)
elif algorithm =='boltzmann':
# ②確率に応じて手を選ぶ(ソフトマックス戦略)確率が大きい要素をランダムに返す。
selected_index = boltzmann(np.array(legal_logits, dtype=np.float32), 0.5)
bestmove = legal_moves[selected_index]
print('bestmove', bestmove.usi())
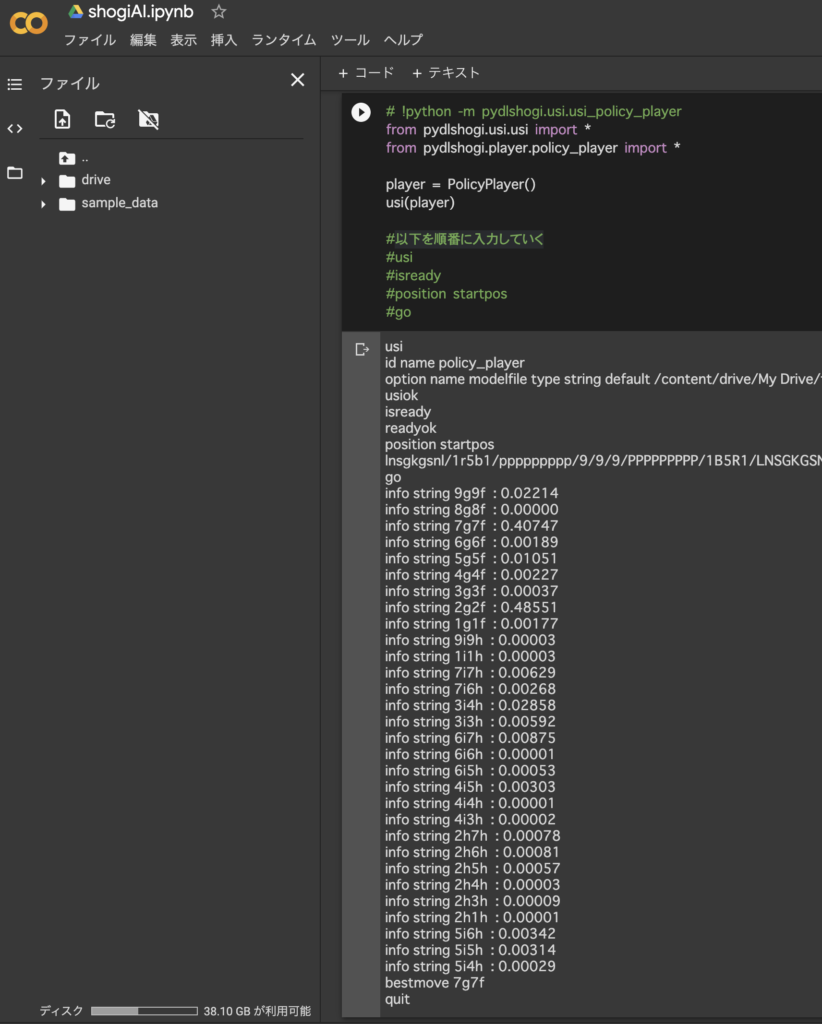
テスト
コマンドラインからテスト
2g2f(2六歩) 0.48551
7g7f(7六歩) 0.40747
2六歩を指した。問題無さそうである。
Google Colabからテスト
今回は7六歩を指した。ソフトマックス戦略により確率の高い手をランダムに指しているようである。問題無し。
USIプロトコルの座標系
9 8 7 6 5 4 3 2 1 筋
段
9a 8a 7a 6a 5a 4a 3a 2a 1a 一
9b 8b 7b 6b 5b 4b 3b 2b 1b 二
9c 8c 7c 6c 5c 4c 3c 2c 1c 三
9d 8d 7d 6d 5d 4d 3d 2d 1d 四
9e 8e 7e 6e 5e 4e 3e 2e 1e 五
9f 8f 7f 6f 5f 4f 3f 2f 1f 六
9g 8g 7g 6g 5g 4g 3g 2g 1g 七
9h 8h 7h 6h 5h 4h 3h 2h 1h 八
9i 8i 7i 6i 5i 4i 3i 2i 1i 九
コメント